
Why eval harnesses belong in week one
Most teams treat evaluation as a post-launch optimisation. By the time launch happens, the team is debugging with vibes and reverting changes based on hunches. The eval set is week-one work, not week-six work.
Every team that has shipped an AI feature into production has had this moment. Somebody on the product side asks "is it getting better or worse this week?" Somebody on the engineering side opens up the playground, runs a few prompts, looks at the outputs, says "feels about the same." Nobody really knows.
That is vibes-based evaluation. It is the default state of most production AI systems we audit, and it is more common than people admit. The team will swear they have evals. Pressed on what the eval set contains, the answer is usually some variant of "we have a list of prompts in a Notion doc" or "we have a script that runs five test cases." That is not an eval harness. That is a smoke test with no meaningful measurement surface.
A real eval harness is something else. It is the thing that lets you ship a change at 3pm on Tuesday and know by 3:15 whether the change made the system better, worse, or roughly equal on the dimensions the team has agreed matter. Without it, every change is a guess. With it, every change is a measurement. The first usable version is achievable in days, not months. The cost of not building it compounds for the rest of the project.
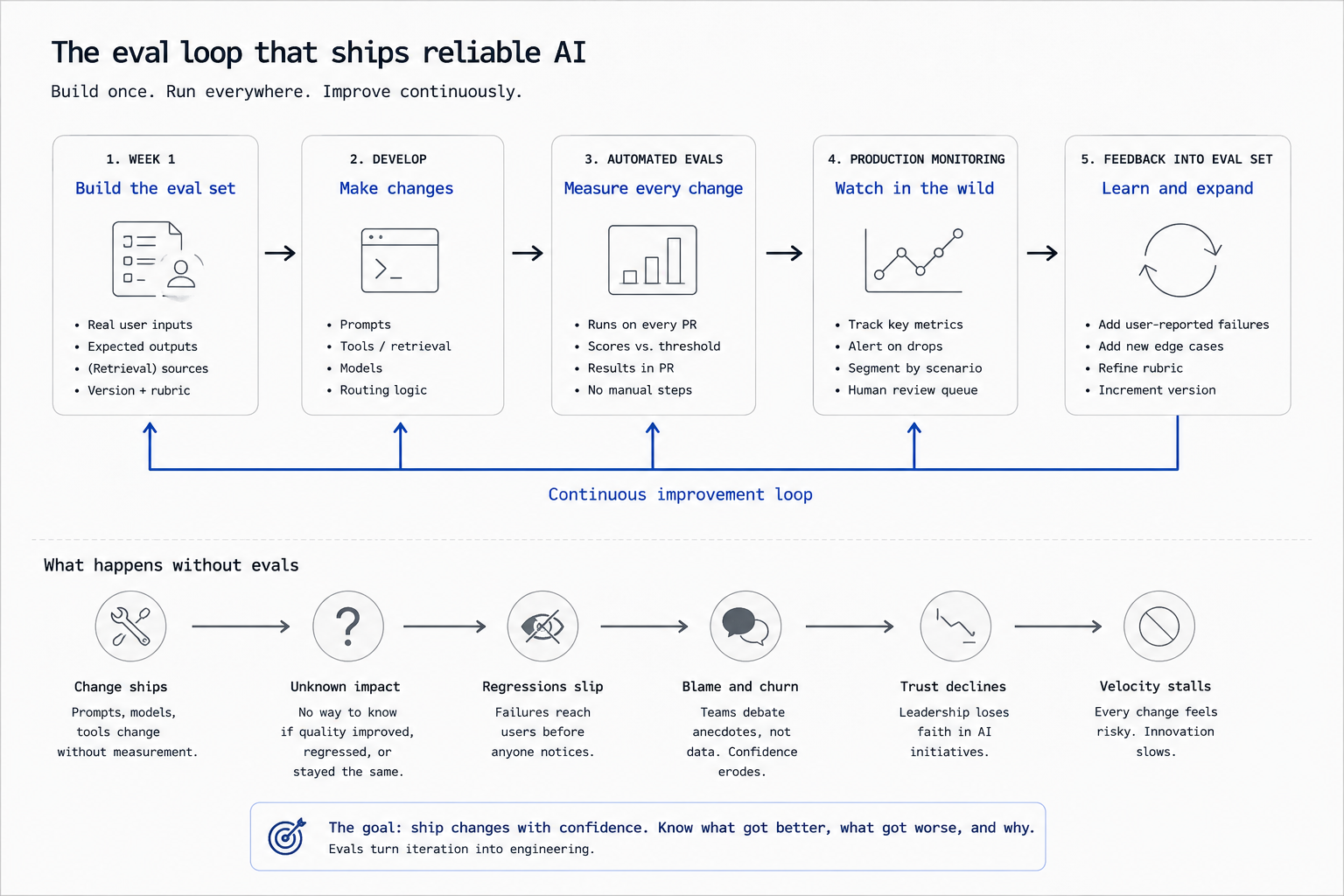
The "we'll add evals later" curse
There is a predictable shape to how AI projects end up without evals.
Week one is the kickoff. The team has a deadline. Building the eval set takes a week of subject-matter expert time that nobody scheduled. Skipping it lets the team start shipping prompts and prototypes. They tell themselves they will add evals once the feature stabilises.
The feature does not stabilise. There is always one more thing to fix. The eval set never gets built. By the time launch arrives, the team is debugging production with screenshots and Slack threads. Every prompt change is a quiet revert away from a regression nobody noticed. The longer this continues, the more invisible the system becomes.
By month six, when the team finally gets around to building the eval set, they have a different problem. They cannot tell which version of the system the eval is supposed to capture. Behavior has drifted. The prompts have been edited dozens of times. The model has been swapped, then swapped back. The eval set, when it finally arrives, is being built against a system that nobody fully understands anymore, including the team that built it.
The eval set has to exist before this drift starts. Otherwise it is not measuring the system; it is reverse-engineering it.
What the eval set actually is
For our work, an eval set has four parts.
A list of real user queries or inputs, drawn from actual conversations, tickets, or recordings (with consent). Synthetic prompts written by the engineering team are worse than nothing. The team's intuition about what users will ask is wrong in ways the team cannot see. Use the real data.
For each input, the expected output. Written by a subject-matter expert. Not "the right answer in general," but "what a knowledgeable human at your company would write in response to this." Sometimes that is a single canonical answer. Sometimes it is a rubric of acceptable answers. Sometimes it is a list of must-include facts and must-not-include errors. The format depends on the task.
For retrieval systems, also a list of the source documents the system should have used. This is what lets you measure retrieval recall separately from generation accuracy, which is what lets you debug the right stage when something fails.
A version number. The eval set will change as you learn what your users actually do. Tracking versions lets you compare results across system changes without conflating them with eval-set changes.
That is the entire artifact. Fifty queries with these four parts is enough to start. A hundred is comfortable. Five hundred is luxurious. Most teams do not have five.
Behavioral evals are different from output evals
There are two layers of evaluation, and conflating them is a common source of confusion.
Output evaluation is what most teams think of first. Did the AI's answer match what the subject-matter expert wrote? Did the agent return the right value? Did the voice system end the call in the right state? This is the most common kind of eval and the easiest to start with.
Behavioral evaluation is harder and often more important. Did the agent take the right path to get there? Did it call the right tools in the right order? Did it ask the user for clarification when it should have? Did it refuse when it should have refused? These are not visible in the final output. They live in the trace of how the system made its decisions.
For simple Q&A or RAG, output evals are usually enough. For agents that call tools, voice systems that route to humans, or any system where the path matters and not just the destination, behavioral evals are what catch the failures users complain about. Most teams do not have them. Most teams should.
LLM-as-judge: useful, but not always
A pattern that has become common is using a large model to grade outputs against expected answers. "Does this output match this reference? Score from 1 to 5." LLM-as-judge.
It works for some tasks. It is unreliable for others. The patterns we have seen:
It works well when the judging criterion is objective and stateable: "does the output contain this factual claim," "does the output mention this person," "is the output in valid JSON matching this schema." A judge model can answer these reliably.
It works badly when the criterion is stylistic, qualitative, or about completeness. "Is this answer helpful?" The judge will mostly say yes. "Is the response professional?" Same. The judge has no calibration on what "helpful" or "professional" means for your users and your domain.
It works worse when the judging criterion involves recency, novelty, or domain knowledge the judge model does not have. A judge model evaluating answers about your internal product will not know what is correct.
The fix is to keep humans in the loop for the criteria where the judge is unreliable, and to use the judge for the criteria where it actually is. Most teams use a single judge prompt for everything and then wonder why the evals do not correlate with user complaints. The correlation is bad because the judge is bad at half the things it is being asked to judge.
When we set up a harness, we tend to split: judge model for objective criteria, human spot-check for the rest, sampled monthly. The human spot-check is the calibration loop that catches when the judge has started lying.
The threshold conversation that should happen before launch
Every production AI system has an implicit accuracy threshold. The team that built it has an opinion. The product team has an opinion. The leadership team has an opinion. These opinions are often not the same, and they are almost never spoken out loud.
That conversation needs to happen before launch.
What accuracy threshold are we willing to ship at? On the eval set, do we ship at 80 percent? 85? 90? What about the long-tail of low-confidence cases: do they go to a human, or does the system attempt and fail? When the accuracy drops below the threshold in production monitoring, who gets paged, and what do we do?
Without this conversation, the team launches the system, the support team starts seeing the failure modes, leadership asks "how did this get through QA," and the engineering team realises there was no QA bar to fail against. The threshold has to be a number, agreed in writing, before the first user touches the feature.
We set this number in week one too, alongside the eval set. The pattern is: pick a number you think is achievable, validate against the eval set, adjust, lock it in. If we cannot hit the threshold by the eval-set milestone, the feature does not ship to users that week. It does not ship until it does.
Continuous evaluation is a discipline, not a tool
Eval harnesses are not a one-time build. They are a habit.
The harness has to run automatically on every change. That means CI integration. Every PR that touches a prompt, a retrieval step, a tool definition, or a model selection should kick off an eval run. The result lands in the PR comments. If accuracy drops below the threshold, the PR cannot merge without an override and a written justification.
The eval set has to grow. Every time a production failure is reported by a user, that failure becomes an eval case. Every time the support team flags an edge case, that case becomes an eval case. The eval set is a record of what the system has been asked to handle, which is more than what the team imagined when they built it.
The harness has to be cheap enough to run often. If a full eval run takes three hours and costs $80, nobody will run it on every PR, and the discipline collapses. Most of the engineering work in a mature eval harness is not the prompts; it is the infrastructure to make the harness fast and cheap. Caching. Batching. Smaller judge models for the bulk of cases. Parallel execution. The mature pattern is a full run nightly, a smoke run on every PR, and a targeted run on every change to a specific subsystem.
What this looks like in week one
When we scope an AI engagement, the first artefact we deliver is not a working agent. It is the eval set.
The first three days are sitting with the subject-matter experts on the client side. We watch them work. We collect the actual queries, the actual edge cases, the cases they think the AI will get wrong. We write down the ground-truth answers in their words. We argue about the rubric where the answer is not binary.
Day four is the threshold conversation. We pick a number. We document the trade-offs of picking different numbers. We get sign-off from product and engineering leadership.
Day five is wiring the harness. CI integration. Cost budget. Cadence. The harness runs nightly from that point on, against whatever the current system is, even if the current system is just a placeholder.
By the end of week one, we have not shipped a feature. We have shipped the ability to know whether any feature we ship after this is better or worse than the last one. That is the entire foundation of the engagement. Everything that comes after is built on it.
Because the work produces measurement instead of visible features, teams routinely postpone it. That postponement compounds for the rest of the project.
The cost of skipping it is not theoretical. We have watched teams spend three months tuning prompts against the wrong success criteria. We have watched A/B tests run for six weeks before someone notices the eval was scoring on something the user did not care about. We have watched leadership lose confidence in AI projects because the team could not answer "is it getting better." The answer to that question is the harness. There is no substitute.
Build the eval set in week one. The rest of the work gets easier from there.