
The latency budget you didn't know you had
Many voice AI and real-time agent projects ship with no explicit latency budget. They discover the budget exists when users start hanging up. The median number is the lie; the p95 is the system.
The first time most teams measure end-to-end latency on a voice AI system, two things happen. First, the median number is reassuring. Then somebody plots the distribution, and the long tail is so heavy that the median is irrelevant. The agent feels great for half the conversations and broken for the other half. Users are not patient enough to average their experience across calls.
Latency is the silent system constraint in voice AI and real-time agentic systems in 2026. Teams design for accuracy and capability, ship the system, and discover only in production that the latency floor was the actual ceiling. This is the failure shape and the things we have learned to think about before the build, not after.
The threshold is harder than it sounds
The number people throw around for natural conversation is 800 milliseconds. The actual research is more specific than that. Humans tolerate pauses of around 200ms in normal conversation. Anything longer than that registers as a pause. Pauses up to about 500ms feel thoughtful. Pauses between 500ms and a second feel hesitant. Pauses past a second feel broken. Past two seconds, users start asking "are you still there."
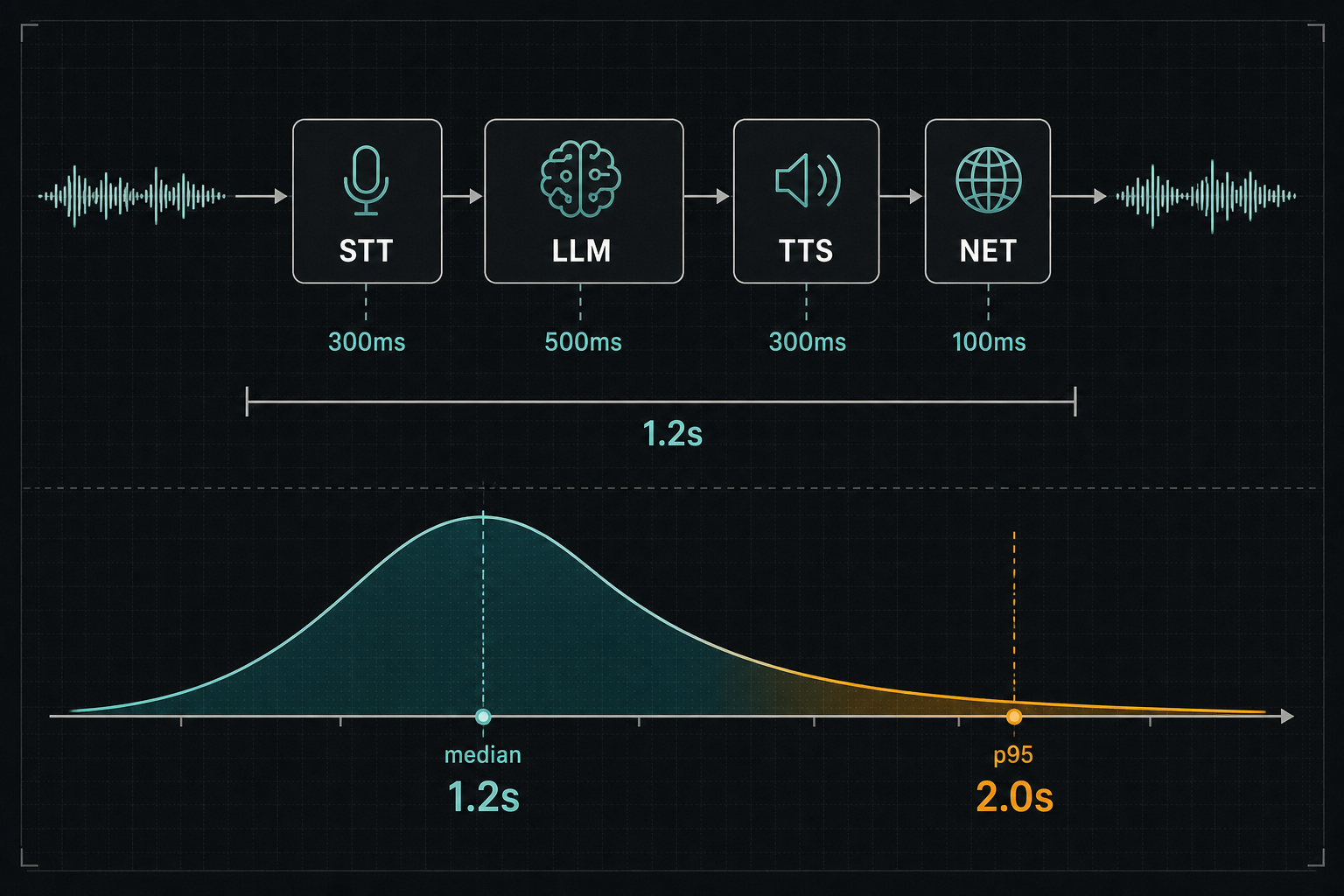
For a voice AI that has to feel like a competent agent, our operating target is response latency under 800ms p95, not p50. The median number you measure in development is not what the user experiences. The user experiences the worst quartile of their own calls. If your p95 is at two seconds, the tail will show up in real calls, and users will start hanging up while your median still looks fine.
The first discipline is to refuse to stop at median. Voice latency is a p95 story. Sometimes a p99 story. The team that ships a voice system with only median measured is the team that ships a broken system and finds out from users.
Where the time actually goes
Voice AI is not one model call. It is a pipeline. Each stage adds latency that the next stage cannot remove.
Speech-to-text. The user speaks. The audio gets transcribed. With streaming STT (Deepgram, AssemblyAI, the cloud providers) the transcript starts arriving in chunks within 200-300ms and the final transcript lands somewhere around when the user stops speaking, often with a 200-500ms tail for the model to commit. With non-streaming STT, you wait until the user finishes, then you submit, then you wait for the whole thing. The non-streaming approach can add a full second to the pipeline for a five-second utterance.
LLM generation. The transcript becomes a prompt. The model thinks. The model emits tokens. If you wait for the entire response before doing anything else, you are paying full token-generation time as a latency cost. If you stream the response into the next stage, you start work on the next stage while the model is still generating.
Text-to-speech. The model's response becomes audio. Modern TTS (ElevenLabs, OpenAI, Google) can stream audio as soon as a sentence's worth of tokens arrives. The audio starts arriving 200-400ms after the tokens start arriving. The user hears the start of the response before the model has finished generating it.
Network. Everything above traverses your infra and the providers' infra. Round-trip times to provider APIs from your hosting region matter. We have seen 100-200ms of latency hidden in routing decisions that were made by accident at deploy time.
Add it up, conservatively: 300ms STT lock + 500ms LLM first-token + 300ms TTS first-audio + 100ms network = 1.2 seconds before the user hears the first syllable of a response, if everything is well-architected. The unstreamed naive version is twice that.
The 800ms target is not casual. It requires the entire pipeline to be working in parallel and the fast path to be wired correctly. Default architectures do not deliver it.
Streaming is the difference
The largest controllable latency win we usually see in voice AI is streaming everything that can be streamed.
Streaming STT means you have a partial transcript while the user is still talking. The agent can start preparing its response on the partial.
Streaming LLM generation means tokens flow out of the model the moment the model has them. You do not wait for the full response.
Streaming TTS means audio begins playing as soon as the first sentence is ready. The user hears the start of the response before generation has finished.
End-to-end streaming compresses the perceived latency to "time until the first byte of audio reaches the user," which can be well under 600ms on a well-architected pipeline. Without streaming, you are measuring "time until the last byte of audio is ready," which is 2-3x longer.
The trade-off is operational complexity. Streaming pipelines have more failure modes, harder error handling, and are more annoying to test. Most teams skip streaming in the first build and add it back when users start hanging up. By then, the pipeline is wired for the blocking pattern and adding streaming is a partial rewrite. Better to design the pipeline streaming from the start, even if the first version only uses part of the streaming capability.
Model choice is a latency lever
The reflex move is to pick the model with the best quality. For voice AI this is usually wrong.
Voice conversations have a specific characteristic: the response does not need to be long. A user asking the agent a question wants a sentence or two back, not a paragraph. The latency cost of a model that takes a thousand milliseconds to generate the first 50 tokens is paid on every turn. The accuracy gain over a model that takes 300ms to generate the first 50 tokens is often invisible to the user, who heard the start of the response 700ms sooner.
For most voice work, the right call is the fastest model that meets the quality bar, not the highest-quality model that fits the latency budget. The difference shows up in the conversation quality the user actually perceives.
We default to model tiering on voice systems for the same reason we default to it on text agents. The classifier that picks "is this a simple lookup or does this need real reasoning" runs in 200ms on a small model. The simple calls stay on the fast model. The calls that need depth route to the better model, with the user being told something brief while the better model thinks. The user is never sitting in silence for two seconds.
Cold start is a real problem
Serverless deployment models save money. They also have cold-start latency that voice AI cannot absorb.
A function that has not been invoked in five minutes can take 500-1000ms to start. Adding 500ms of cold-start to the front of a pipeline that has 800ms of legitimate work in it makes the user wait 1300ms for the first response. The conversation feels broken from turn one.
The patterns that fix this:
Provisioned concurrency. Pay to keep a warm instance running. Cheaper than the user hanging up.
Long-running services. For voice work, just run a long-lived process instead of a serverless function. The latency floor is dramatically lower because there is no cold start. Fly.io, Render, an EC2 instance, whatever. The savings on serverless cost are not worth the latency floor.
Edge deployment. The model providers run their own edge inference. Your routing layer can run at the edge too. Keeping the inference and the orchestration close to each other shaves real milliseconds off every turn.
The serverless-by-default pattern that works fine for web apps often does not work for latency-critical voice turns. The architecture decision has to be made deliberately.
Voice-specific design choices
A few things that make a voice system tolerable that are not relevant for text systems:
Acknowledgment phrases. While the system is thinking on a complex query, it can say "let me check that for you" within 200ms of the user finishing. This buys you several seconds of model time without the user feeling like the system is broken. The acknowledgment is generated by a tiny model with five canned phrases, not by the same model doing the real work.
Confidence thresholds with verbal fallbacks. When the agent is not confident in its answer, the response is "let me transfer you to someone who can confirm this," not a confidently-wrong response. In high-stakes workflows, users usually prefer the transfer to a confident wrong answer.
Aggressive interruption handling. The user starts talking; the system stops talking. This is hard with TTS in flight and is often skipped in the first build. It is the difference between a voice system that feels alive and one that feels like an automated phone menu. Worth the engineering cost.
End-of-utterance detection. Knowing when the user has stopped talking is its own subsystem. Get it wrong and the system either cuts the user off mid-thought or waits four seconds after they stopped to start responding. Tune this against real audio from your users, not the synthetic test cases.
The "good enough" line
There is a temptation to over-engineer voice latency. Once you have measured the pipeline and it consistently delivers under-800ms p95 first-syllable latency, more optimization is usually wasted engineering.
Past that point, the user-perceptible improvements come from non-latency dimensions: response quality, handling of interruptions, emotional appropriateness of the voice, graceful handling of unclear audio. These are where the work goes after the latency floor is achieved. Squeezing the latency from 600ms p95 to 500ms p95 is real work and is rarely the right work.
The line is: ship when p95 is under 800ms reliably, then move on to other dimensions of quality. Do not chase milliseconds past the threshold humans care about.
Where this leaves you
If you are building voice AI or any real-time agent system, the order to think about it:
- Pick the latency target as p95, not median. 800ms first-syllable latency for natural conversation. Higher targets are acceptable if the use case is more transactional and less conversational.
- Design the pipeline streaming from the start. Even if the first version is not fully streaming, the architecture should support it without a rewrite.
- Pick the model based on the latency budget, not the leaderboard. The fastest model that hits the quality bar is the right model.
- Address cold start before launch. Provisioned concurrency or long-running services. Not serverless for voice work.
- Build the operational layer: acknowledgments, interruption handling, end-of-utterance, fallback phrasing. These are the difference between alive and broken.
The teams that treat latency as the dominant constraint from week one ship voice systems users want to talk to. The teams that treat latency as an optimisation problem to be addressed after the build ship voice systems users hang up on.
The latency budget exists whether you measure it or not. Measuring it early is cheap. Discovering it late is expensive.